Interpretability Creationism
For centuries, Europeans agreed that the presence of a cuckoo egg was a great honor to a nesting bird, as it granted an opportunity to exhibit Christian hospitality. The devout bird enthusiastically fed her holy guest, even more so than she would her own (evicted) chicks (Davies, 2015). In 1859, Charles Darwin’s studies of another occasional brood parasite, finches, called into question any rosy, cooperative view of bird behavior (Darwin, 1859). Without considering the evolution of the cuckoo’s role, it would have been difficult to recognize the nesting bird not as a gracious host to the cuckoo chick, but as an unfortunate dupe. The historical process is essential to understanding its biological consequences; as evolutionary biologist Theodosius Dobzhansky put it, Nothing in Biology Makes Sense Except in the Light of Evolution.

Certainly SGD is not literally biological evolution, but post-hoc analysis in machine learning has a lot in common with scientific approaches in biology, and likewise often requires an understanding of the origin of model behavior. Therefore, the following holds whether looking at parasitic brooding behavior or at the inner representations of a neural network: if we do not consider how a system develops, it is difficult to distinguish a pleasing story from a useful analysis.
Just-So Stories
We have many pleasing just-so stories in NLP. Much has been made of interpretable artifacts such as syntactic attention distributions or selective neurons. But how can we know if such a pattern of behavior is actually used by the model? Causal modeling can help, but interventions to test the influence of particular features and patterns may target only particular types of behavior explicitly. In practice, it may be possible only to perform certain types of slight interventions on specific units within a representation, failing to reflect interactions between features properly. Furthermore, in staging these interventions, we create distribution shifts that a model may not be robust to, regardless of whether that behavior is part of a core strategy. Significant distribution shifts can cause erratic behavior, so why shouldn’t they cause spurious interpretable artifacts? In practice, we find no shortage of incidental observations construed as crucial.
Fortunately, the study of evolution has provided a number of ways to interpret the artifacts produced by a model. They might be vestigial, like a human tailbone. They may have dependencies, with some features and structures relying on the presence of other properties earlier in training, like the requirement for light sensing before a complex eye can develop. Some artifacts might represent side effects of training, like how junk DNA constitutes a majority of our genetic code without influencing our phenotypes.
We have a number of theories for how such unused artifacts might emerge while training models. For example, the Information Bottleneck Hypothesis predicts how inputs may be memorized early in training, before representations are compressed to only retain information about the output. These early memorized interpolations may not ultimately be useful when generalizing to unseen data, but they are essential in order to eventually learn to specifically represent the output. We also can infer the possibility of vestigial features, because early training behavior is so distinct from late training: earlier models are more simplistic. In the case of language models, they behave similarly to ngram models early on and exhibit linguistic patterns later. Side effects of such a heteroskedastic training process could easily be mistaken for crucial components of a trained model.
The Evolutionary View
I may be unimpressed by “interpretability creationist” explanations of static fully trained models, but I have engaged in similar analysis myself. I’ve published papers on probing static representations, and the results often seem intuitive and explanatory. However, the presence of a feature at the end of training is hardly informative about the inductive bias of a model on its own! Consider Lovering et al., who found that the ease of extracting a feature at the start of training, along with an analysis of the finetuning data, has deeper implications for finetuned performance than we get by simply probing at the end of training.
Let us consider an explanation usually based on analyzing static models: hierarchical behavior in language models. An example of this approach is the claim that words that are closely linked on a syntax tree have representations that are closer together, compared to words that are syntactically farther. How can we know that the model is behaving hierarchically by grouping words according to syntactic proximity? Alternatively, syntactic neighbors may be more strongly linked due to a strong correlation between nearby words because they have higher joint frequency distributions. For example, perhaps constituents like “football match” are more predictable due to the frequency of their co-occurrence, compared to more distant relations like that between “uncle” and “football” in the sentence, “My uncle drove me to a football match”. In fact, we can be more confident that some language models are hierarchical, because early models encode more local information in LSTMs and Transformers, and they learn longer distance dependencies more easily when those dependencies can be stacked onto short familiar constituents hierarchically.
An Example
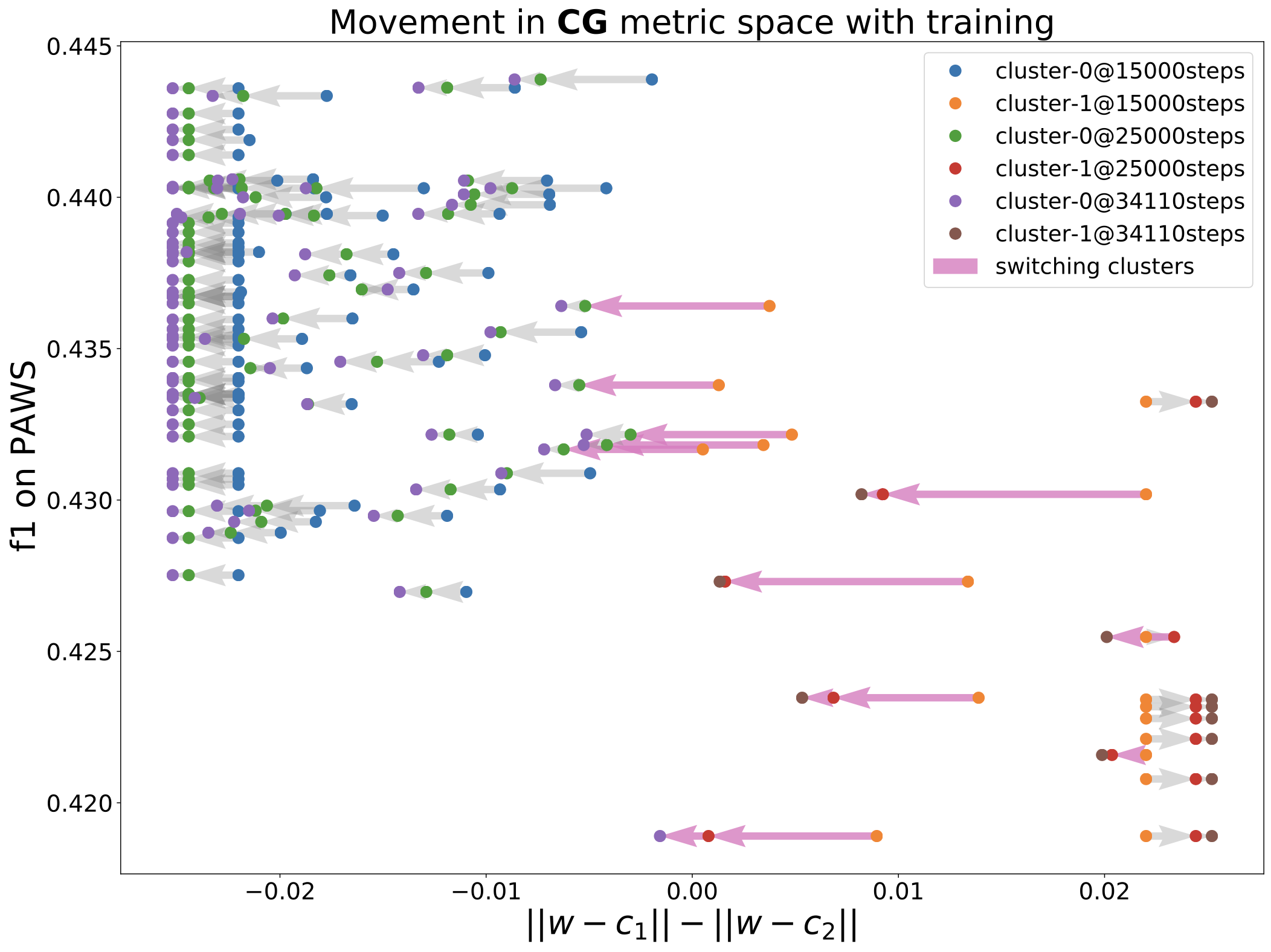
I recently had to manage the trap of interpretability creationism myself. My coauthors had found that, when training text classifiers repeatedly with different random seeds, models can occur in a number of distinct clusters. Further, we could predict the generalization behavior of a model based on which other models it was connected to on the loss surface. Now, we suspected that different finetuning runs found models with different generalization behavior because their trajectories entered different basins on the loss surface.
But could we actually make this claim? What if one cluster actually corresponded to earlier stages of a model? Eventually those models would leave for the cluster with better generalization, so our only real result would be that some finetuning runs were slower than others. We had to demonstrate that training trajectories could actually become trapped in a basin, providing an explanation for the diversity of generalization behavior in trained models. Indeed, when we looked at several checkpoints, we confirmed that models that were very central to either cluster would become even more strongly connected to the rest of their cluster over the course of training. Instead of offering a just-so story based on a static model, we explored the evolution of observed behavior to confirm our hypothesis.

A Proposal
To be clear, not every question can be answered by only observing the training process. Causal claims require interventions! In biology, for example, research about antibiotic resistance requires us to deliberately expose bacteria to antibiotics, rather than waiting and hoping to find a natural experiment. Even the claims currently being made based on observations of training dynamics may require experimental confirmation.
Furthermore, not all claims require any observation of the training process. Even to ancient humans, many organs had obvious purpose: eyes see, hearts pump blood, and brains are refrigerators. Likewise in NLP, just by analyzing static models we can make simple claims: that particular neurons activate in the presence of particular properties, or that some types of information remain accessible within a model. However, the training dimension can still clarify the meaning of many observations made in a static model.
My proposal is simple. Are you developing a method of interpretation or analyzing some property of a trained model? Don’t just look at final checkpoint in training. Apply that analysis to several intermediate checkpoints. If you are finetuning a model, check several points both early and late in training. If you are analyzing a large language model, MultiBERTs and Mistral both provide intermediate checkpoints sampled from throughout training on masked and autoregressive language models, respectively. Does the behavior that you’ve analyzed change over the course of training? Does your belief about the model’s strategy actually make sense after observing what happens early in training? There’s very little overhead to an experiment like this, and you never know what you’ll find!